Если предыдущая проблема извлечения данных с Hibernate была связана с большим количеством select, то на этот раз select будет один. Но какой: если select содержит два и более join, это приводит к выборке огромного количества лишних данных, которые передаются по сети, занимают оперативную память. Что также отрицательно сказывается на производительности. И таких join-ов тоже надо избегать. Ниже рассмотрим пример.
Когда возникает проблема
Столкнуться с проблемой можно как явно (просто написав Query с несколькими join), так и неявно, выполнив find() для сущности с EAGER-коллекциями (Hibernate при этом сгенерирует SQL с несколькими join).
В обоих случаях с точки зрения объектной модели мы хотим получить сущность вместе с заполненными полями коллекций.
Модель
Допустим, у нас есть пост с двумя коллекциями — тегов и картинок:
@Data
@NoArgsConstructor
@Entity
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private long id;
private String title;
@OneToMany(mappedBy = "post", cascade = CascadeType.ALL)
private List<Image> images=new ArrayList<>();
@ElementCollection
private Set<String> tags = new HashSet<>();
public Post(String title){
this.title=title;
}
public void addImage(Image image){
image.setPost(this);
this.images.add(image);
}
}
Коллекция тегов — @ElementCollection, коллекция картинок — двунаправленной отношение @OneToMany. На факт возникновения проблемы вид коллекции не влияет (и отношение @ManyToMany тоже способно вызвать проблему).
Класс картинки:
@Data
@NoArgsConstructor
@Entity
public class Image {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private long id;
private String url;
@ManyToOne
private Post post;
public Image(String url){
this.url=url;
}
}
По умолчанию поля коллекций заполняются лениво:
fetch = FetchType.LAZY
И это правильно, иначе при выборке Post мы столкнемся с N+1 select проблемой.
Но как же получить обе коллекции и при этом избегнуть как N+1 проблему, так и select-а c двумя join (Cartesian product problem)?
Ответ прост — нужно выполнить вместо одного select с несколькими join (в нашем случае двумя) несколько select-ов (в нашем случае два — по одному на коллекцию), в каждом из который ровно один join.
Как получить сущность с коллекциями и избежать проблемы декартова произведения
До выполнения теста давайте заполним базу постами, в каждом из которых — коллекция с двумя картинками и пятью тегами:
public class CartesianProblemTest {
@BeforeAll
private static void createPosts() {
HibernateUtil.doInHibernate(session -> {
for (int i = 0; i < 5; i++) {
Post post = new Post("topic" + i);
Image image1 = new Image("url1_" + i);
Image image2 = new Image("url2_" + i);
post.addImage(image1);
post.addImage(image2);
Set<String> tags = Arrays.asList("red", "green", "blue", "orange", "white").stream().collect(Collectors.toSet());
post.setTags(tags);
session.persist(post);
}
});
}
//тесты
}
Теперь попытаемся получить пост с картинками и тегами, соблюдая наше требование избегнуть обеих проблем.
Для этого получаем коллекции по очереди. В первом select — получим коллекцию картинок, а во втором — тегов.
@Test
@DisplayName("если FetchType.LAZY и выполнить отдельные select для заполнения коллекций, то проблемы нет")
public void givneLazy_whenSelectCollectionsByOne_thenOk() {
HibernateUtil.doInHibernate(session -> {
List<Post> posts = session
.createQuery(
"select distinct p " +
"from Post p " +
"left join fetch p.images " +
"where p.id between :minId and :maxId ", Post.class)
.setParameter("minId", 1L)
.setParameter("maxId", 1L)
.setHint(QueryHints.PASS_DISTINCT_THROUGH, false)
.getResultList();
posts = session
.createQuery(
"select distinct p " +
"from Post p " +
"left join fetch p.tags t " +
"where p in :posts ", Post.class)
.setParameter("posts", posts)
.setHint(QueryHints.PASS_DISTINCT_THROUGH, false)
.getResultList();
});
В итоге поля коллекций будут заполнены.
После выполнения тесты в консоли мы увидим два select, в каждом из которых по одному join:
select post0_.id as id1_1_0_, images1_.id as id1_0_1_, post0_.title as title2_1_0_, images1_.post_id as post_id3_0_1_, images1_.url as url2_0_1_, images1_.post_id as post_id3_0_0__, images1_.id as id1_0_0__ from Post post0_ left outer join Image images1_ on post0_.id=images1_.post_id where post0_.id between ? and ? --------------------------------------------- select post0_.id as id1_1_, post0_.title as title2_1_, tags1_.Post_id as Post_id1_2_0__, tags1_.tags as tags2_2_0__ from Post post0_ left outer join Post_tags tags1_ on post0_.id=tags1_.Post_id where post0_.id in (?)
И это вполне терпимо, в отличии от нескольких join в одном select. Поскольку каждый join умножает количество выбранных строк на количество элементов в коллекции. Ниже показано, как.
Cartesian product
На всякий случай продемонстрирую проблему наглядно, показав выборку, которую Hibernate автоматически формирует при выполнении find().
Для этого временно изменим fetch = FetchType.EAGER для обоих коллекций (чтобы коллекции в принципе заполнялись, ведь наша задача состоит в этом):
@OneToMany(mappedBy = "post", cascade = CascadeType.ALL, fetch = FetchType.EAGER) private List<Image> images = new ArrayList<>(); @ElementCollection(fetch = FetchType.EAGER) private Set<String> tags = new HashSet<>();
И выберем всего одну запись с помощью find():
@Test
@DisplayName("если поставить FetchType.EAGER, то find создает большой Cartesian Product ")
public void givenEager_whenFind_thenCartesianProblem() {
HibernateUtil.doInHibernate(session -> {
Post post = session.find(Post.class, 1l);
});
}
Вот что генерирует в консоли Hibernate:
select post0_.id as id1_1_0_, post0_.title as title2_1_0_, images1_.post_id as post_id3_0_1_, images1_.id as id1_0_1_, images1_.id as id1_0_2_, images1_.post_id as post_id3_0_2_, images1_.url as url2_0_2_, tags2_.Post_id as Post_id1_2_3_, tags2_.tags as tags2_2_3_ from Post post0_ left outer join Image images1_ on post0_.id=images1_.post_id left outer join Post_tags tags2_ on post0_.id=tags2_.Post_id where post0_.id=?
Как видно выше, это select с двумя join.
Если выполнить его на базе (выбираем один пост с двумя картинками и пятью тегами), получим такую выборку:
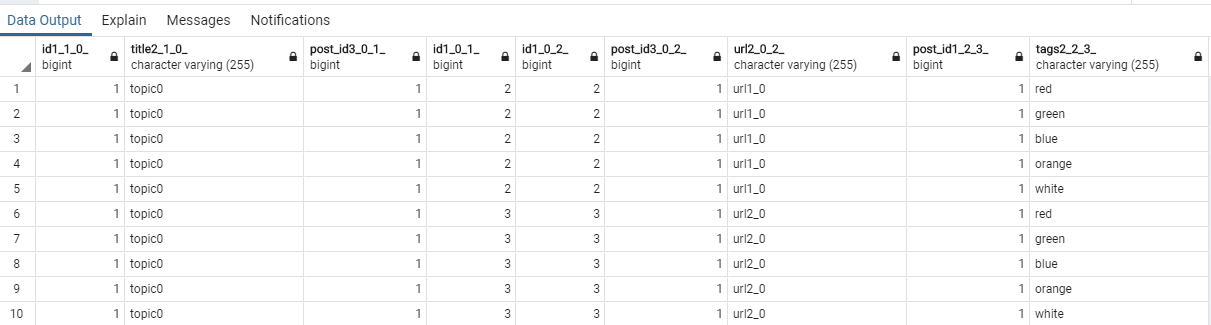
В ней дублируется информация, и это плохо.
Еще один способ: FetchMode.SUBSELECT
И рассмотрим еще один способ заполнить коллекции постов, при этом избажав проблемы как декартова произведения, так и N+1.
Для этого аннотируем обе коллекции с @Fetch(FetchMode.SUBSELECT):
@OneToMany(mappedBy = "post", cascade = CascadeType.ALL) @Fetch(FetchMode.SUBSELECT) private List<Image> images = new ArrayList<>(); @ElementCollection @Fetch(FetchMode.SUBSELECT) private Set<String> tags = new HashSet<>();
Выполним тест и получим три SQL-запроса в консоли:
@Test
@DisplayName("если поставить org.hibernate.annotations.FetchMode.SUBSELECT, и сделать обычный select, то тоже пофиксим проблему")
public void givenSubselect_whenSimpleSelect_thenOk() {
List<Post> returnedPosts = HibernateUtil.doInHibernate(session -> {
List<Post> posts = session.createQuery("select p from Post p", Post.class).getResultList();
//достаточно обратиться к коллекциям одного элемента, чтобы заполнились коллекции всех элементов
System.out.println(posts.get(0));
return posts;
});
Assertions.assertEquals(5, returnedPosts.size());
returnedPosts.forEach(System.out::println);
}
Генерируемые SQL-запросы:
select post0_.id as id1_1_, post0_.title as title2_1_
from Post post0_
------------------------------------------
select images0_.post_id as post_id3_0_1_, images0_.id as id1_0_1_,
images0_.id as id1_0_0_, images0_.post_id as post_id3_0_0_,
images0_.url as url2_0_0_
from Image images0_
where images0_.post_id in (select post0_.id from Post post0_)
--------------------------------------
select tags0_.Post_id as Post_id1_2_0_, tags0_.tags as tags2_2_0_
from Post_tags tags0_
where tags0_.Post_id in (select post0_.id from Post post0_)
На этот раз после выборки постов выбираются все картинки и все теги для все выбранных постов. Причем делается это только после обращения к коллекциям одного поста:
System.out.println(posts.get(0));
Если к коллекциям одного поста не обратиться, то никакие коллекции загружены не будут. Если же обратиться, то будут загружены коллекции для все выбранных постов. Вот так работает FetchMode.SUBSELECT.
Итоги
Исходный код примера есть на GitHub.
То же самое на Spring см. тут.
А как сделать все то же самое, но только в проекте из жизни, а не как в вашем примере, а именно, используя JpaRepository, native-qiery, сервисные методы и т. д.? Ну, то есть то, что используется во всех реальных проектах, в которых никто не использует createQuery() и т. д.
Просто прописать в репозиториях те же запросы (что сейчас в createQuery()) внутри аннотаций @Query. В статье пример не на Spring, поэтому тут этого нет, но со Spring, JpaRepository и @Query было бы еще проще.
а разве можно одному методу повесить две аннотации @Query??
не, два метода в отдельные @Query, и заключить их в один @Transactional сервисный метод. См. пример тут