Ключевое слово DISTINCT есть как в JPQL, так и в SQL. В SQL оно устраняет дубликаты строк, а в JPQL — дубликаты объектов.
Рассмотрим оба примера: как фильтрации списка объектов на уровне Hibernate, так и фильтрации списка строк на уровне базы данных.
Модель
Допустим у нас есть топик с комментариями в отношении OneToMany:
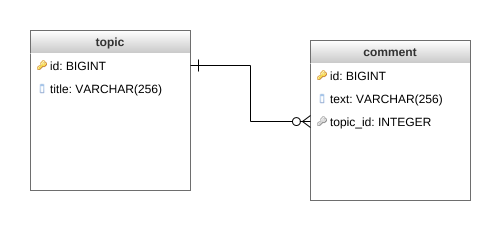
Класс Topic:
@Data
@NoArgsConstructor
@Entity
public class Topic {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private long id;
private String title;
@OneToMany(mappedBy = "topic", cascade = CascadeType.ALL, orphanRemoval = true)
private Set<Comment> comments=new HashSet<>();
...
}
Класс Comment:
@NoArgsConstructor
@Data
@Entity
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;
private String text;
@ManyToOne(fetch = FetchType.LAZY)
private Topic topic;
public Comment(String text) {
this.text = text;
}
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (!(o instanceof Comment)) return false;
return id != null && id.equals(((Comment) o).getId());
}
@Override
public int hashCode() {
return 31;
}
}
JPQL Запрос
Мы хотим получить список топиков вместе с комментариями единым запросом. Для этого используем ключевые слова LEFT JOIN FETCH:
public interface TopicRepository extends JpaRepository<Topic, Long> {
@Query("select t from Topic t left join fetch t.comments")
List<Topic> getTopicsWithComments();
}
Но возникает проблема: если выполнить JOIN между сущностью и ее коллекцией, то в возвращаемом списке будут дубликаты.
Наш JPQL -запрос преобразуется в следующий SQL с LEFT OUTER JOIN:
select topic0_.id as id1_1_0_, comments1_.id as id1_0_1_, topic0_.title as title2_1_0_, comments1_.text as text2_0_1_,
comments1_.topic_id as topic_id3_0_1_, comments1_.topic_id as topic_id3_0_0__, comments1_.id as id1_0_0__
from topic topic0_ left outer join comment comments1_
on topic0_.id=comments1_.topic_id
Об SQL LEFT OUTER JOIN
LEFT OUTER JOIN значит:
- Декартово произведение множеств строк топиков и строк комментариев — это всевозможные комбинации каждого топика с каждым комментарием (иначе говоря CROSS JOIN).
- Применение к полученным комбинациям логического условия в ON — topic.id=comment.topic_id. Оставляем только те комбинации (строки), где условие выполняется.
- Добавляем невключенные в итоговый результат топики с нулевым числом комментариев (потому что указано ключевое слово LEFT), поля комментариев для этих строк заполняем null.
Данные, результат запроса, а также зачем нужен DISTINCT
Изначально мы заполнили базу тремя топиками, и к первому добавили три комментария:
insert into topic (id, title) values (-1,'title1'); insert into topic (id, title) values (-2,'duplicated title'); insert into topic (id, title) values (-3,'duplicated title'); insert into comment (id, text, topic_id) values (-4, 'text1', -1); insert into comment (id, text, topic_id) values (-5, 'text2', -1); insert into comment (id, text, topic_id) values (-6, 'text3', -1);
В результате LEFT JOIN получаем 5 строк:
-1 title1 -4 text1 -1 -1 title1 -5 text2 -1 -1 title1 -6 text3 -1 -2 duplicated title null null null -3 duplicated title null null null
В них первый топик встречается трижды (он скомбинирован с тремя комментариями).
И без ключевого слова DISTINCT в результирующий List<Topic> пойдет 5 топиков (топик с id=-1 будет встречаться трижды со своими тремя комментариями)! Чтобы убрать дубликаты, надо использовать ключевое слово DISTINCT.
Запрос с DISTINCT
Изменим запрос, добавив в него DISTINCT:
@Query("select distinct t from Topic t left join fetch t.comments")
List<Topic> getTopicsWithComments();
Теперь выполним тест и получим три топика:
public void whenFindwithDistinct_thenNoDuplicates() {
List<Topic> topics = topicRepository.getTopicsWithComments();
Assertions.assertEquals(3, topics.size());
}
Что и требовалось.
Генерируемый SQL:
select distinct topic0_.id as id1_1_0_, comments1_.id as id1_0_1_, topic0_.title as title2_1_0_, comments1_.text as text2_0_1_,
comments1_.topic_id as topic_id3_0_1_, comments1_.topic_id as topic_id3_0_0__, comments1_.id as id1_0_0__
from topic topic0_ left outer join comment comments1_
on topic0_.id=comments1_.topic_id
Надо сказать, что distinct в SQL в нашем случае число строк не сокращает. Поскольку все полученные строки различаются хотя бы одним полем (см. выше вывод результата из 5 строк). Удаление дубликатов происходит на уровне Hibernate.
Query Hint hibernate.query.passDistinctThrough
Значит можно DISTINCT из SQL убрать. Он передается в него по умолчанию. Чтобы DISTINCT не передавался из JPQL в SQL, добавим аннотацию @QueryHint:
@QueryHints(value = { @QueryHint(name = "hibernate.query.passDistinctThrough", value = "false")})
@Query("select distinct t from Topic t left join fetch t.comments")
List<Topic> getTopicsWithComments();
DISTINCT в SQL
А теперь рассмотрим пример, когда DISTINCT в SQL имеет смысл. Например, выберем все возможные названия топиков без дубликатов:
@Query("select distinct t.title from Topic t")
List<String> getUniqueTopicTitles();
Генерируется SQL:
select distinct topic0_.title as col_0_0_ from topic topic0_
У нас два из трех title одинаковые, так что должно получиться два (title1 и duplicated title):
@Test
public void whenGetTopicNames_thenSQLDistinct() {
List<String> titles = topicRepository.getUniqueTopicTitles();
Assertions.assertEquals(2, titles.size());
}
Итоги
Исходный код есть на GitHub.