По мере разработки и поддержки приложения база данных изменяется: добавляются таблицы, столбцы и т.д. Для упрощения отслеживания изменений существует Liquibase. Мы делегируем выполнение скриптов этой библиотеке, а она в начале запуска приложения решает, надо ли на конкретной базе выполнить конкретные скрипты, или же они в ней уже выполнены.
Как работает Liquibase
Работает Liquibase так: программист записывает все SQL-изменения базы данных в специальном Liquibase-формате (xml, yaml, json, sql — на выбор). А библиотека Liquibase (у нас это maven-зависимость) запускает эти изменения. При этом Liquibase отслеживает саму себя — какие скрипты она уже запускала, а какие еще нет. Для этого она создает в нашей базе две служебные таблицы, в которых хранятся идентификаторы скриптов с датой запуска и т.п. И при запуске Spring Boot приложения Liquibase сама решает, какие скрипты выполнять, а какие нет.

В итоге получается, что при запуске приложения на пустой базе, она заполнится (таблицами и данными, которые есть в скриптах) и накатятся все изменения (которые есть в скриптах). А при запуске приложения на заполненной базе последней версии, скрипты не накатятся. При запуске же приложения на частично устаревшей базе, накатятся только те скрипты, которые еще не выполнялись. Отлично, теперь не надо помнить, на какой базе уже выполнены скрипты, а на какой нет. Устраняется путаница.
Сначала рассмотрим ситуацию, когда база уже есть, и мы хотим перенести ее в Liquibase-формат. То есть чтобы при запуске приложения с пустой базой она создавалась с нуля.
Перенос существующей базы данных в Liquibase-формат
Это можно сделать с помощью maven-плагина, но мы рассмотрим, как сгенерировать файл со скриптами (у нас он будет называться master.yaml) из командной строки. Для этого нужно установить на компьютер Liquibase.
Затем в любой папке компьютера создаем файл liquibase.properties с:
- параметрами доступа к базе,
- путем до драйвера,
- именем выходного файла (например, master.yaml)
- названием папки с данными базы.
Например, для PostgreSQL-базы можно положить драйвер postgresql-42.2.14.jar прямо в ту же папку, где находится файл liquibase.properties. А в файле liquibase.properties написать:
username=postgres password=mypassword url=jdbc:postgresql://localhost/mydbname driver=org.postgresql.Driver classpath=postgresql-42.2.14.jar changeLogFile=master.yaml dataOutputDirectory=data
Затем из командной строки выполним:
liquibase generateChangeLog
В итоге получим в этой же папке файл master.yaml с описанием структуры базы, а в папке data этой же папки — данные в формате csv. По одному файлу на таблицу базы.
Пример сгенерированного скрипта
Пусть в нашем приложении есть единственная сущность Animal:
@Entity
public class Animal {
@Id
@GeneratedValue(strategy= GenerationType.SEQUENCE)
private long id;
private String name;
}
которой соответствует таблица animal в базе. В таблице две строки.
После запуска команды:
liquibase generateChangeLog
содержимое master.yaml будет таким:
databaseChangeLog:
- changeSet:
id: 1596784098744-1
author: myluc (generated)
changes:
- createTable:
columns:
- column:
constraints:
nullable: false
primaryKey: true
primaryKeyName: animal_pkey
name: id
type: BIGINT
- column:
name: name
type: VARCHAR(255)
tableName: animal
- changeSet:
id: 1596784098744-2
author: myluc (generated)
changes:
- loadData:
columns:
- column:
header: id
name: id
type: NUMERIC
- column:
header: name
name: name
type: STRING
commentLineStartsWith: '#'
encoding: UTF-8
file: data/animal.csv
quotchar: '"'
separator: ','
tableName: animal
- changeSet:
id: 1596784098744-3
author: myluc (generated)
changes:
- createSequence:
cacheSize: 1
cycle: false
dataType: bigint
incrementBy: 1
maxValue: 9223372036854775807
minValue: 1
sequenceName: hibernate_sequence
startValue: 3
Тут три changeSet (каждому соответствует свой идентификатор):
- создание таблицы animal
- заполнение ее данными из файла data/animal.csv
- создание sequence (для генерации идентификаторов id, так как в сущности @Animal мы используем strategy= GenerationType.SEQUENCE)
Таким образом всё, что есть в базе, перенеслось в набор changeSet-ов.
Теперь внесем в Spring Boot приложение зависимость Liquibase, настроим и ее на запуск полученных changeSet-ов. Так при запуске Spring Boot приложения на пустой базе она будет заполняться таблицами и данными с нуля.
Заполнение базы из Liquibase-файлов с приложением Spring Boot
Мы слегка переделаем master.yaml, отделив создание таблицы и последовательности от создания данных. Это нужно для того, чтобы в будущем было проще дополнять changeSet-ы со своими изменениями.
Maven-зависимость
Во-первых, надо добавить в Spring Boot приложение Maven-зависимость:
<dependency> <groupId>org.liquibase</groupId> <artifactId>liquibase-core</artifactId> </dependency>
Настройки в application.yml
Во-вторых, чтобы библиотека Liquibase выполняла невыполненные скрипты при запуске приложения, в application.yml необходимо ее включить (enabled=true):
spring: liquibase: enabled: true change-log: classpath:db/changelog/db.changelog-master.yaml contexts: dev
db/changelog/db.changelog-master.yaml — это имя и путь до нашего master.yaml. Имя/путь длинные, но зато эту строку можно на самом деле не указывать, так как именно это имя и этот путь используется в Liquibase по умолчанию. Так что переименуем файл master.yaml в файл db.changelog-master.yaml и положим по указанному пути в папку resources.
Структура папок
Таким образом, структура папок такая (наш сгенерированный master.yaml переименован в db.changelog-master.yaml). И сгенерированная папка data с csv-файлом вложена в data:
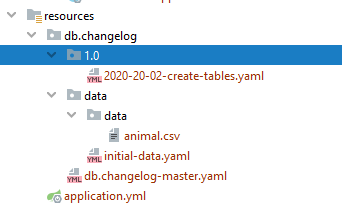
Мастер-файл db.changelog-master.yaml
Вместо трех changeSet-ов в главный файл db.changelog-master.yaml поместим пути до папок, которые будут пополняться скриптами с со структурой и данными базы (при этом имена файлов не указываем, загружаются все, что есть в папке).
databaseChangeLog:
- includeAll:
path: db/changelog/1.0/
- includeAll:
path: db/changelog/data/
По пути db/changelog/1.0/ сейчас лежит один файл 2020-20-02-create-tables.yaml.
2020-20-02-create-tables.yaml — создание структуры базы
В него мы скопируем два сгенерированных changeSet-а из трех: а именно, создание таблицы и создание последовательности. Таким образом, содержимое файла такое:
databaseChangeLog:
- changeSet:
id: 1596784098744-1
author: myluc (generated)
changes:
- createTable:
columns:
- column:
constraints:
nullable: false
primaryKey: true
primaryKeyName: animal_pkey
name: id
type: BIGINT
- column:
name: name
type: VARCHAR(255)
tableName: animal
- changeSet:
id: 1596784098744-3
author: myluc (generated)
changes:
- createSequence:
cacheSize: 1
cycle: false
dataType: bigint
incrementBy: 1
maxValue: 9223372036854775807
minValue: 1
sequenceName: hibernate_sequence
startValue: 3
initial-data.yaml — загрузка данных
Файл initial-data.yaml отвечает за загрузку данных. В него скопирован третий changeSet:
databaseChangeLog:
- changeSet:
id: 1596784098744-2
author: myluc (generated)
changes:
- loadData:
columns:
- column:
header: id
name: id
type: NUMERIC
- column:
header: name
name: name
type: STRING
commentLineStartsWith: '#'
encoding: UTF-8
file: data/animal.csv
quotchar: '"'
separator: ','
relativeToChangelogFile: true
tableName: animal
Запуск Spring Boot приложения
Теперь приложение можно запускать на новой пустой базе. (Предварительно нужно только создать саму базу с нужным именем и прописать к ней spring.datasource настройки в application.yml).
При первом запуске Spring Boot приложения Liquibase заполнит базу, а также создаст две служебные таблицы Liquibase. В них сохранится сам факт запуска скриптов с данными идентификаторами. Поэтому при втором запуске Spring Boot приложения на этой базе Liquibase не будет повторно выполнять скрипты.
Как отделить скрипты для тестовой базы
- changeSet:
id: ...
author: ...
context: test
....
Этот changeSet выполнится только в тестовой базе.
Откуда взялось значение test? Оно прописывается в файле application.yaml, в данном случае в том, что находится в папке тестов test:
liquibase: enabled: true change-log: classpath:db/changelog/db.changelog-master.yaml contexts: test
Если же changeSet надо выполнить в обоих контекстах (в тестовой и основной базе — например, это может быть создание таблицы), то помечаем его так:
- changeSet:
id: ...
author: ...
context: dev or test
....
При этом контекст dev прописан в основном application.yaml папки main:
liquibase: enabled: true change-log: classpath:db/changelog/db.changelog-master.yaml contexts: dev
Итоги
Теперь наше Spring Boot приложение с maven-зависимостью Liquibase, включенной настройкой spring.liquibase.enabled=true и размещенными в ресурсах changeSet-ами можно запускать на пустой базе. При первом запуске база будет заполнена, при последующих запусках останется такой же.
Исходный код примера есть на GitHub: там Spring Boot приложение с готовыми Liquibase-скриптами.
После запуска можно проверить содержимое служебной таблицы databasechangelog. В ней столбец id — это идентификаторы changeSet-ов из yaml-файлов. При первом запуске приложения таблица будет заполнена (как показано на первой картинке статьи). По этой таблице Liquibase будет знать, что changeSet-ы с такими идентификаторами выполнены, и не будет выполнять их во второй раз при новых запусках приложения на этой же базе.
По мере развития проекта и изменения базы новые yaml-файлы можно добавлять в папки db/changelog/1.0/ и db/changelog/data/ — Liquibase подхватит и выполнит эти файлы.