Spring Batch предоставляет интерфейс для пакетной обработки данных. Например – конвертация данных из одной базы в другую, из файла в базу, из брокера сообщений в файл и т.д. и т.п. Эти задания могут выполняться разово или по расписанию.
В Spring Batch эти задания можно масштабировать: настроить выполнение в нескольких потоках или даже на нескольких jvm.
Также можно настраивать политики пропуска элементов или же, наоборот, попыток их повторной обработки (тут подробнее).
Кроме того, Spring Batch позволяет в случае возникновения исключения перезапустить задание не с самого начала, а с проблемного места: есть много готовых способных на это реализаций (для File, JDBC, NoSQL, JMS). Ниже мы рассмотрим пример с FlatFileItemReader.
Чтение, обработка и запись элементов
FlatFileItemReader — это «считыватель» элементов, реализация ItemReader для файла. FlatFileItemReader считывает данные построчно. Если на какой-то строке выбросится исключение, то при перезапуске задания (Job) данные будут считываться не с нуля, а с проблемной строки (если быть точнее, то с начала порции (chunk), содержащей проблемную строку).
Вообще ItemReader — один из основных интерфейсов Spring Batch — он предназначен для чтения элементов. Есть также ItemProcessor и ItemWriter — для обработки и записи элементов.
Данные можно разбивать на порции. Согласно архитектуре Spring Batch, каждая порция обрабатывается в отдельной транзакции (порции — chunks, подробнее тут). Размер порции настраивается в зависимости от задачи.
Задача
Как говорилось, у нас для чтения данных из файла используется FlatFileItemReader, способный сохранять ход выполнения задания. Так что если для задания Job при попытке его выполнения JobExecution возникнет исключение, новая попытка начнется не с начала. Мы это увидим на примере.
Это входной файл input.csv:
1,dog 2,cat 3,fox 4,elephant 5,eagle 6,squirrel 7,tiger 8,shark
Наша задача — считать данные из файла input.csv, преобразовать название животного в верхний регистр и записать результат в файл output.json в JSON-формате:
[
{"id":"1","name":"DOG"},
{"id":"2","name":"CAT"},
{"id":"3","name":"FOX"},
{"id":"4","name":"ELEPHANT"},
{"id":"5","name":"EAGLE"},
{"id":"6","name":"SQUIRREL"},
{"id":"7","name":"TIGER"},
{"id":"8","name":"SHARK"}
]
Для записи будем использовать JsonFileItemWriter — тоже готовую реализацию, но ItemWriter.
У нас 8 строк, размер порции зададим равным 3. Тогда если исключение возникнет в 5 строке (а мы сделаем, что возникнет), будут обработаны все равно только 3 строки. Они сохранятся в выходном файле. Остальные будут дописаны только при перезапуске задания.
Подготовка
Maven-зависимость
Чтобы начать работать с Spring Batch, добавим в проект:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency>
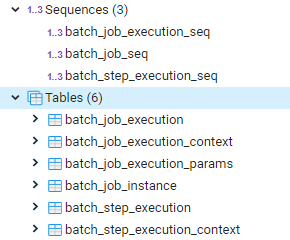
Кроме того, нам понадобится база данных. Дело в том, что Spring Batch хранит в служебных таблицах в базе задания Job, попытки их выполнения JobExecution и многое другое — всего 6 таблиц.
В нашем примере используется PostgreSQL, но можно добавить любую базу. Главное, чтобы после запуска программы можно было посмотреть содержимое служебных таблиц, мы будем на них ссылаться в статье.
Создание служебных таблиц
Spring Boot создает служебные таблицы Spring Batch автоматически, если в настройках указать:
spring.batch.initialize-schema=always
Теперь при первом запуске приложения в базе появятся таблицы:
Конфигурация задания Job
Ниже рассмотрим конфигурацию задания Spring Batch. По умолчанию сконфигурированное задание Job запускается на старте приложения, но часто это неудобно. Мы будем запускать задание с помощью JobLauncher — заодно рассмотрим, как задать параметры задания и какое значение они имеют. Чтобы отключить автозапуск, в настройках зададим:
spring.batch.job.enabled=false
Задание Job
Задание задается как бин:
@Bean
public Job job(Step step) {
return jobs.get("job")
.start(step)
.build();
}
Оно состоит из шагов. Вообще можно задать несколько шагов, но у нас один.
Шаг Step
В шаге задается ItemReader, ItemWriter и ItemProcessor:
@Bean
public Step step(ItemReader<Animal> csvItemReader, ItemWriter<Animal> jsonItemWriter) throws IOException {
// @formatter:off
return steps
.get("step1")
.<Animal, Animal>chunk(3)
.reader(csvItemReader)
.processor(animalItemProcessor())
.writer(jsonItemWriter)
.build();
// @formatter:on
}
Также задан размер порции равным три. По три элемента обрабатываются в одной транзакции.
ItemReader (FlatFileItemReader)
Здесь мы настраиваем FlatFileItemReader — указываем для него файл и mapper:
@Bean
@StepScope
public FlatFileItemReader<Animal> csvItemReader(@Value("#{jobParameters['file.input']}") String input) {
FlatFileItemReaderBuilder<Animal> builder = new FlatFileItemReaderBuilder<>();
FieldSetMapper<Animal> animalFieldSetMapper = new AnimalFieldSetMapper();
// @formatter:off
return builder
.name("animalReader")
.resource(new FileSystemResource(input))
.delimited()
.names(TOKENS)
.fieldSetMapper(animalFieldSetMapper)
.build();
// @formatter:on
}
AnimalFieldSetMapper:
public class AnimalFieldSetMapper implements FieldSetMapper<Animal> {
@Override
public Animal mapFieldSet(FieldSet fieldSet) throws BindException {
Animal animal = new Animal();
animal.setId(fieldSet.readString("id"));
animal.setName(fieldSet.readString("name"));
return animal;
}
}
ItemProcessor
ItemProcessor у нас просто при водит имя к верхнему регистру:
@Bean
@StepScope
ItemProcessor<Animal, Animal> animalItemProcessor() {
return animal -> {
LOGGER.info("Processing " + animal.getName());
animal.setName(animal.getName().toUpperCase());
return animal;
};
}
ItemWriter (JsonFileItemWriter)
В качестве ItemWriter тоже берем готовую реализацию — JsonFileItemWriter:
@Bean
@StepScope
public JsonFileItemWriter<Animal> jsonItemWriter(@Value("#{jobParameters['file.output']}") String output) throws IOException {
JsonFileItemWriterBuilder<Animal> builder = new JsonFileItemWriterBuilder<>();
JacksonJsonObjectMarshaller<Animal> marshaller = new JacksonJsonObjectMarshaller<>();
// @formatter:off
return builder
.name("animalWriter")
.jsonObjectMarshaller(marshaller)
.resource(new FileSystemResource(output))
.build();
// @formatter:on
}
Запуск задания с помощью JobLauncher
Выше в настройках мы отключили автозапуск задания при старте приложения. Запускать мы будем его все равно при старте, но сами — с помощью JobLauncher:
@SpringBootApplication
public class Main implements CommandLineRunner {
@Autowired
private Job job;
@Autowired
private JobLauncher jobLauncher;
@Value("${file.input}")
private String input;
@Value("${file.output}")
private String output;
public static void main(String[] args) {
SpringApplication.run(Main.class, args);
}
@Override
public void run(String... args) throws Exception {
JobParametersBuilder jobParameters = new JobParametersBuilder();
jobParameters.addString("file.input", input);
jobParameters.addString("file.output", output);
jobParameters.addString("trial","1");
jobLauncher.run(job, jobParameters.toJobParameters());
}
}
Как видно выше, в качестве параметров мы задаем входной и выходной файл, а также trial — номер попытки, ниже покажу зачем.
При запуске задание выполняется успешно, в базе мы получаем строку в таблице batch_job_instance:

и строку в batch_job_execution:

JobInstanceAlreadyCompleteException
Но если повторно запустить программу, сделано ничего не будет, вместо этого выбросится исключение:
Caused by: org.springframework.batch.core.repository.JobInstanceAlreadyCompleteException: A job instance already exists and is complete for parameters={file.input=src/main/resources/input.csv, file.output=src/main/resources/output.json, trial=1}. If you want to run this job again, change the parameters.
Потому что для данного JobInstance успешный JobExecution (то есть JobExecution со статусом COMPLETED) может быть только один.
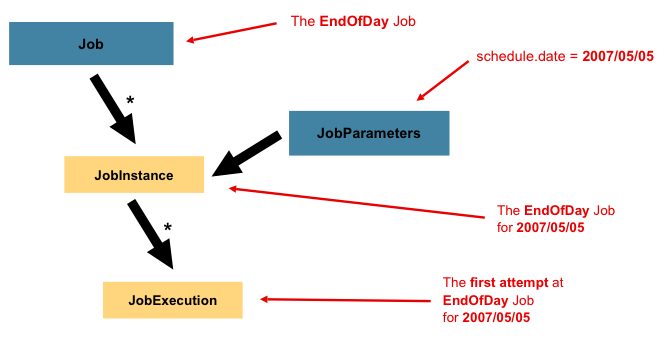
Как создать новый JobInstance
Но что, если задание нужно выполнить неоднократно? Для этого нужен новый JobInstance. Он будет создан, если поменять хотя бы один параметр задания, например :
jobParameters.addString("trial","2");
Соотношение Job и JobInstance иллюстрируется картинкой из документации:
Часто (например, при запуске задания по расписанию с @Scheduled) добавляют автоматически генерируемый уникальный параметр:
.addLong("launchTime", System.currentTimeMillis())
Но мы изменили параметр вручную (поставили другой номер для trial). Теперь приложение можно запустить вновь и задание выполнится с нуля повторно. В базе появится второй JobInstance, а для него — новый JobExecution.
Может ли для одного JobInstance быть несколько JobExecution? Да: успешный JobExecution (со статусом COMPLETED) должен быть единственным, но со статусом FAILED их может быть много. Если бы при предыдущем запуске возникло исключение и задание не выполнилось, результат JobExecution был бы FAILED. Тогда были бы разрешены новые попытки выполнения задания, и каждый раз в таблицу добавлялся бы новый JobExecution для старого JobInstance (до тех пор, пока не получится COMPLETED). Эти попытки называются рестартом задания — и это как раз та самая уникальная возможность Spring Batch, позволяющая повторить задание с проблемной точки, а не с нуля.
Рестарт
Давайте сделаем рестарт. Для этого надо сначала получить JobExecution в статусе FAILED, а потом исправить ошибку и попробовать снова.
Получение JobExecution в статусе FAILED
Чтобы вызвать исключение, исправим исходный файл, чтобы при парсинге 5 строки возникло исключение:
1,dog 2,cat 3,fox 4,elephant ,,,5,eagle 6,squirrel 7,tiger 8,shark
Теперь запустим приложение (только не забудьте поменять параметр trial, ведь задание у нас считается уже успешно выполненным и больше выполняться не будет. Нужно, чтобы создался новый JobInstance, который еще не выполнен (для него еще нет JobExecution в статусе COMPLETED). Так что цифру ставить надо ту, с которой еще не запускали приложение:
jobParameters.addString("trial","2");
В таблице появится еще один JobExecution, и он получит статус FAILED:

Обработается три элемента, поскольку .chunk(3):
Executing step: [step1] ru.sysout.batch.BatchConfig : Processing dog ru.sysout.batch.BatchConfig : Processing cat ru.sysout.batch.BatchConfig : Processing fox o.s.batch.core.step.AbstractStep : Encountered an error executing step step1 in job job org.springframework.batch.item.file.FlatFileParseException: Parsing error at line: 5 in resource=[file [C:\Code\sysout\batch0\src\main\resources\input.csv]], input=[,,,5,eagle]
В выходном файле будет три элемента.
В таблице batch_step_execution видно, что считано 4 элемента, записано 3 и выполнен 1 commit:

Поскольку JobExecution для последнего JobInstance имеет статус FAILED, можно перезапустить задание с теми же параметрами (по сути выполнить тот же JobInstance снова). Будет создан новый JobExecution. Причем задание начнет выполняться не сначала, а с проблемной точки.
А теперь рестарт
Только сделаем входной файл снова нормальным, чтобы задание прошло успешно.
1,dog 2,cat 3,fox 4,elephant 5,eagle 6,squirrel 7,tiger 8,shark
И запустим приложение с тем же значением параметра trial.
Задание выполнится успешно. При этом:
- В консоли видно, что обрабатываются 4-8 элементы. Первые три заново не обрабатываются:
Processing elephant Processing eagle Processing squirrel Processing tiger Processing shark
- Новый batch_job_instance не появляется в базе.
- А появляется новый batch_job_execution в статусе COMPLETED (для старого batch_job_instance).
- В таблице batch_step_execution добавляется строка, где видно, что считаны и записаны оставшиеся 5 элементов, выполнено 2 commit:

Итоги
Мы рассмотрели основные понятия Spring Batch и что такое рестарт задания. Исходный код примера есть на GitHub.
Подскажите, можно реализовать Spring Batch как бесконечный цикл? Т.е. на вход периодически поступает массив с данными, обрабатывается сохраняется в другом виде для отображения на фронте и возможно передается куда-то дальше. Конечно необходима возможности запуска такого цикла и временной остановки.
Причем первый и третий шаги должны работать с фиксированной частотой, например 20мсек, второму а второму достаточно и периода в 1сек, чтобы сильно не нагружать систему.
Т.е. получается , что третий шаг получает данные с первого и работает с такой же частотой. Второй шаг тоже берет данные у первого, но можно запускать его раз в 100 реже.
Как считаете подойдет для реализации такой задачи Spring Batch? Или лучше использовать что-то другое от Spring? Или третий вариант реализовать собственные потоки.