В этой статье рассмотрим уровни изоляции на примере задачи: написать веб-приложение с одной веб-страницей, которое выдает число обращений к ней (или хитов).
Таблица
Пусть это число хранится в таблице hits PostgreSQL с одной строкой:
data.sql:
insert into hits (id, count) values (1, 0);
Число хитов хранится в поле count, начальное значение 0. Каждое обращение к веб-странице должно увеличивать значение в поле count на 1.
Сервис и репозиторий
При запросе страницы идет обращение к сервису, который, в свою очередь, обращается к репозиторию HitRepository:
@Transactional(propagation = Propagation.REQUIRED)
@Repository
public interface HitRepository extends CrudRepository<Hits, Long> {
@Query("select id, count from hits where id=:id")
Hits getCount(long id);
@Modifying
@Query("update hits set count=count+1 where id=:id")
void updateCount(long id);
}
Сервис HitService:
@Service
public class HitService {
@Autowired
private HitRepository hitRepository;
@Transactional(isolation = Isolation.READ_COMMITTED)
public HitsDto updateAndReturnCount() {
hitRepository.updateCount(1l);
Hits hits = hitRepository.getCount(1l);
return HitsDto.fromHits(hits);
}
}
Веб-приложение создает отдельный поток для каждого запроса, таким образом обращение к методу updateAndReturnCount() из контроллера (его напишем ниже) будет идти из нескольких потоков. И можно протестировать параллельные транзакции.
@Transactional
Метод сервиса аннотирован @Transactional, уровень изоляции указан:
isolation = Isolation.READ_COMMITTED
Но его можно и не указывать, поскольку в PostgreSQL это уровень, используемый по умолчанию. Он бы и так использовался.
Методы репозитория тоже аннотированы @Transactional с propagation:
(propagation = Propagation.REQUIRED)
Но propagation тоже можно было не указывать, поскольку значение Propagation.REQUIRED — значение по умолчанию. Оно означает, что когда методы репозитория вызываются из @Transactional-метода, новая транзакция для них не создается, а используется та, что снаружи. Вообще propagation нужен, если один @Transactional-метод вызывается из другого — чтобы указать, создавать ли для внутреннего метода отдельную транзакцию или использовать существующую, как вообще реагировать на наличие/отсутствие внешней транзакции (можно еще выбросить исключение, если она есть либо ее нет, можно выполнить метод вне транзакции и другие редкие варианты).
Таким образом, у нас транзакция будет одна, создается она в методе сервиса updateAndReturnCount(), и уровень изоляции для нее READ_COMMITTED.
Контроллер
Создадим веб-страницу, которая выдает число (оно также выводится в консоль):
@RestController
public class MainController {
@Autowired
private HitService hitService;
@GetMapping("/")
public HitsDto main() {
HitsDto hitsDTO = hitService.updateAndReturnCount();
System.out.println(hitsDTO.getCount());
return hitsDTO;
}
}
Результат верный
Если протестировать приложение с помощью JMeter (у меня создано 500 потоков), то заметим, что подсчет идет правильно, в консоль выводятся значения счетчика, и это последовательные числа.
Происходит это потому, что update блокирует модифицируемую строку от параллельных update до конца транзакции. (От параллельных select не блокирует, но поскольку select стоит после update, параллельные select и не вызываются, пока транзакция не закончится.) Все происходит последовательно.
Если поменять местами select и update
Если же поставить select перед update:
@Service
public class HitService {
@Autowired
private HitRepository hitRepository;
@Transactional(isolation = Isolation.READ_COMMITTED)
public HitsDto updateAndReturnCount() {
Hits hits = hitRepository.getCount(1l); //теперь эта строка первая
hitRepository.updateCount(1l); //а эта вторая
return HitsDto.fromHits(hits);
}
}
то возникнет ошибка. Числа будут выводиться не всегда последовательно.
Это происходит потому, что два потока могут одновременно войти и считать одно и то же старое значение, а уж потом приступить к update (и update выполнятся по очереди). select не блокирует запись от параллельных считываний и модификаций. Вот update блокирует запись от параллельных update до конца транзакции.
Поэтому в базе update будет вести подсчет правильно, но вот select (а значит и сервисный метод) может выдавать ложные значения.
Проиллюстрировать этот вариант можно так (начальное значение count=1 до обеих транзакций):
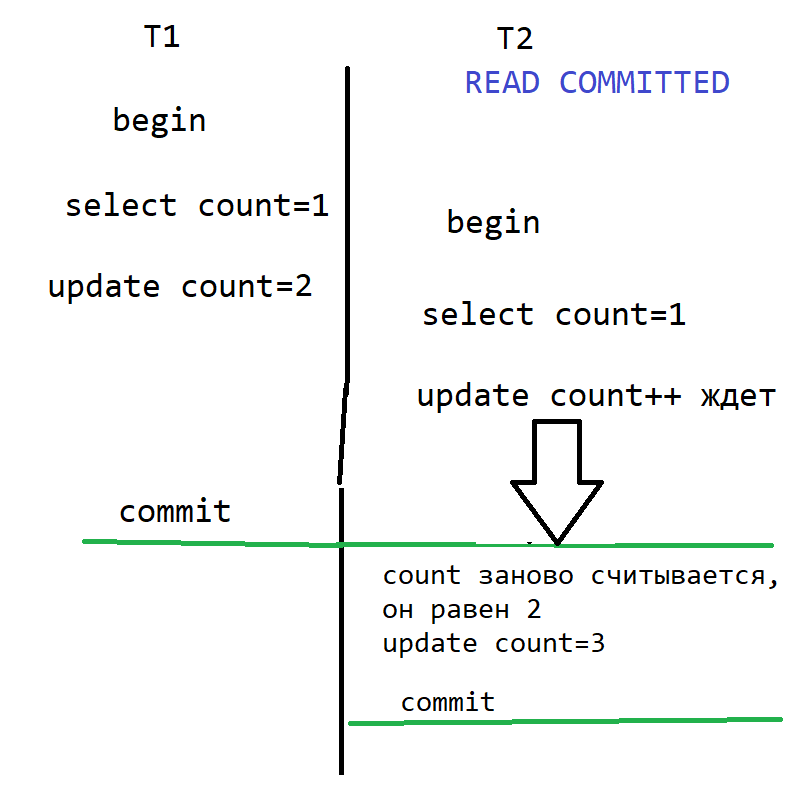
- T1 начинается.
- T1 выбирает count, он равен 1.
- T2 начинается.
- T1 изменяет count, прибавляя к нему 1 (теперь он равен 2) и блокирует ее от параллельных update до конца T1.
- T2 выбирает count, он равен 1 (не проблема, что строка в процессе модификации, от чтения то блокировки нет. Считывается старое подтвержденное (committed) значение 1.
- T2 пытается изменить count (сделать ее count=2), но обнаруживает, что строка заблокирована, и надо ждать окончания параллельной транзакции.
- T1 делает commit, а значит T2 может продолжить работу.
- T2 заново считывает строку и обнаруживает, что она поменялась. (Но id, по которому ищем строку, такой же, так что строка находится). К новому значению count прибавляется 1. Теперь count=3.
- T2 делает commit.
В итоге две транзакции увеличили count на 2 (каждая на один), что правильно. Итоговый count=3. Но вот select вернул в обоих случаях 1. Так что программа в таблице считает запросы верно, а в контроллере (и в консоли) выдает не всегда последовательные значения.
REPEATABLE READ
Попробуем поменять уровень изоляции метода на REPEATABLE_READ
@Transactional(isolation = Isolation.REPEATABLE_READ)
public HitsDto updateAndReturnCount() {
Hits hits = hitRepository.getCount(1l);
hitRepository.updateCount(1l);
return HitsDto.fromHits(hits);
}
Этот уровень требует повторяемого чтения, то есть теперь нашу транзакцию не устроит тот случай, когда update пересчитал значение и обнаружил, что оно не такое, как в select (и вообще не такое, как в начале транзакции). Но к сожалению, это «не устроит» реализуется с помощью отката и исключения. Так что если установить в JMeter 500 тредов, чтоб случилась параллельная транзакция, то возникнет исключение, и вместо подсчета номера запроса вернется страница ошибки. В общем последовательность будет такая:
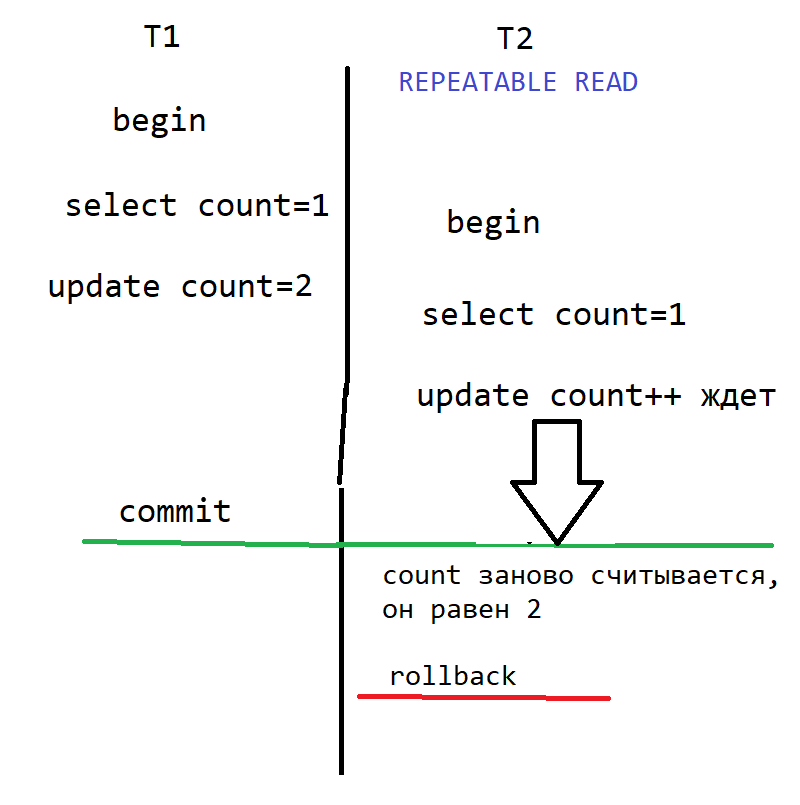
Разница с предыдущим случаем выделена жирным:
- T1 начинается.
- T1 выбирает count, он равен 1.
- T2 начинается.
- T1 изменяет count, прибавляя к нему 1 (теперь он равен 2) и блокирует ее от параллельных update до конца T1.
- T2 выбирает count, он равен 1 (не проблема, что строка в процессе модификации, от чтения то блокировки нет. Считывается старое подтвержденное (committed) значение.
- T2 пытается изменить count (сделать ее count=2), но обнаруживает, что строка заблокирована, и надо ждать окончания параллельной транзакции.
- T1 делает commit, а значит T2 может продолжить работу.
- T2 заново считывает строку и обнаруживает, что она поменялась. (Но id, по которому ищем строку, такой же, так что строка находится). Поскольку уровень изоляции REPEATABLE_READ, транзакцию T2 не устраивает, что значение поменялось по сравнению с тем, что было до начала T2.
- T2 делает rollback.
Проблема в том, что программа будет время от времени выдавать страницу ошибки при возникновении параллельной транзакции вместо того, чтобы учесть и посчитать запрос:
org.postgresql.util.PSQLException: ОШИБКА: не удалось сериализовать доступ из-за параллельного изменения
Хотя числа в консоль будут выдаваться строго последовательно.
Надо сказать, что если сделать update первым, а select вторым и оставить уровень REPEATABLE_READ, то конфликт и откат все равно будет. update не перенесет, что запись изменилась параллельной транзакцией независимо от того, где он расположен.
Явная блокировка select .. for update
Но можно ли как-то разместить сначала select, а потом update, и чтобы все работало? Да, если использовать явную блокировку select for update. Явная блокировка — не оптимистичная, она не надеется, что конфликт не возникнет. Она просто заставит параллельный select подождать.
Результат будет идентичен первому варианту, когда сначала идет update, а потом select Итак, теперь в репозитории метод getCount() использует явную блокировку:
@Transactional(propagation = Propagation.REQUIRED)
@Repository
public interface HitRepository extends CrudRepository<Hits, Long> {
@Query( "select id, count from hits where id=:id for update")
Hits getCount(long id);
@Modifying
@Query("update hits set count=count+1 where id=:id")
void updateCount(long id);
}
Она блокирует как параллельные select for update, так и update, то есть заставляет их ждать до конца своей транзакции. То есть до конца этой транзакции:
@Transactional(isolation = Isolation.READ_COMMITTED)
public HitsDto updateAndReturnCount() {
Hits hits = hitRepository.getCount(1l);
hitRepository.updateCount(1l);
return HitsDto.fromHits(hits);
}
При этом тоже нужен уровень изоляции READ_COMMITTED, при REPEATABLE_READ транзакция не стерпит, что значение уже кто-то параллельно менял. Хоть select for update и будет ждать.
Итоги
Мы рассмотрели аннотацию @Transactional и простое приложение, которое иллюстрирует влияние уровня изоляции на корректность результата.
Код примера на GitHub.
Про настройку propagation аннотации @Transactional можно почитать тут.
Как же классно вы описываете сложные вещи!
Они реально становятся простыми.
Респект за статью очень понятные примеры
Прошу прощения, ткните пальцем, где используется явная блокировка (какой строчкой)?
Строка 4 в первом примере из 8 раздела: select id, count from hits where id=:id for update — этой командой ставится явная блокировка
Благодарю. На ‘for update’ не обратил сразу внимание
Отличная статья, многое ставит для меня на свои места.
Есть один момент, не совсем ясный в разделе 6 о REPEATABLE READ .
«теперь нашу транзакцию не устроит тот случай, когда update пересчитал значение и обнаружил, что оно не такое, как в select (и вообще не такое, как в начале транзакции)».
Если я правильно понимаю, то транзакцию не устроит только то, что значение count не такое, как в начале транзакции только для updateCount метода. А на то, что происходит в getCount(т.е. в select), методу updateCount все равно.
Было бы здорово прочитать в отдельной статье сценарий использования REPEATABLE_READ и SERIALIZABLE 😉