Создать новую аннотацию в Java легко. Также легко аннотировать ею класс, метод или другой элемент. Но толку от этого кода будет мало, поскольку для любой аннотации нужен обработчик. И вот тут все становится намного сложнее, поскольку написать можно совершенно разные обработчики аннотаций, и они могут обрабатывать аннотацию на разных этапах — от компиляции до времени выполнения кода.
Есть обработчики, которые на основе аннотаций трансформируют уже скомпилированные .class файлы. Пример — обфускатор. Можно пометить своей аннотаций классы, которые не надо трогать, и написать обработчик, который опирается на аннотацию, чтобы решить, трансформировать ли класс. Другой пример — обработчик, который логирует вызов аннотированных методов, мы его написали здесь.
Есть обработчики, которые в RUNTIME меняют код с помощью библиотеки Java Reflection.
В этой статье мы рассмотрим, как обрабатывать аннотации на самом начальном уровне — в исходниках, еще до компиляции файлов.
RetentionPolicy.SOURCE
Для этого уровня достаточно, чтобы аннотация имела RetentionPolicy.SOURCE, например:
@Retention(RetentionPolicy.SOURCE)
@Target(ElementType.METHOD)
public @interface ToString {
}
Это означает, что аннотация доступна только в исходниках, а в .class-файлах и в RUNTIME ее уже нет.
Еще пример — аннотация @Override на переопределенных методах:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
Чем полезны аннотации уровня SOURCE
Итак, чем же нам может быть полезна дополнительная обработка исходного кода?
Например, можно выполнить дополнительные проверки кода на валидность. Пример — создать аннотацию @Debug и пометить ей код, который не должен идти в продакшн. То есть надо проверять код на наличие аннотаций @Debug, и если они найдены, то прерывать компиляцию с соответствующим соообщением.
Можно на основе аннотаций генерировать дополнительный исходный код, который программисту лень писать. Пример — в JPA генерируются новые классы на основе аннотаций, программист эти классы писать не должен. В проекте Lombok генерируются сеттеры и геттеры также на основе аннотаций. (Хотя в Lombok меняются существующие классы, что является хаком. Мы рассматриваем обработчик, который предназначен прежде всего для генерации нового класса, а не изменения существующего).
Но не обязательно генерировать исходный код, можно генерировать ресурсы, код на C++, в общем — любые файлы.
Как написать свой обработчик аннотаций
Возможность написать обработчик аннотаций с помощью стандартной библиотеки Java появилась c 6-ой версии, для этого надо расширить класс
javax.annotation.processing.AbstractProcessor
В готовом виде наш обработчик — это отдельное приложение, то есть jar-файл (с определенной метаинформацией, о которой написано ниже), который передается компилятору в classpath. Если компилятор находит такой обработчик, то он запускает его в отдельной Java VM, и наш обработчик дополнительно обрабатывает исходники.
Наша задача
В этой статье мы напишем приложение, которое генерирует новый класс. Допустим, у нас есть приложение, и нем бин:
public class Cat {
private String breed;
private int id;
private String name;
public void setBreed(String breed) {
this.breed = breed;
}
public void setId(int id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
@ToString
public String getBreed() {
return breed;
}
@ToString
public String getName() {
return name;
}
}
Некоторые геттеры помечены аннотаций @ToString, код которой уже приводился выше.
Мы напишем второе приложение-обработчик, которое передается как параметр при компиляции первого:
javac -processor обработчик.jar
На этапе компиляции обработчик сгенерирует дополнительный класс ToStrings, содержащий статический метод toString() для бина Cat. Метод выводит информацию о бине на основе помеченных с помощью аннотацией геттеров:
public class ToStrings {
public static String toString(Cat cat) {
return cat.getName() + "," + cat.getBreed();
}
}
Унаследуемся от AbstractProcessor
Итак, как было сказано выше, чтобы написать обработчик, надо унаследоваться от класса AbstractProcessor:
@SupportedAnnotationTypes("ru.sysout.annotationprocessing.ToString")
public class AnnotationProcessor extends AbstractProcessor {
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv)
{
for (TypeElement annotation : annotations) {
Set<? extends Element> annotatedElements = roundEnv.getElementsAnnotatedWith(annotation);
// ...
}
return true;
}
}
В строке
@SupportedAnnotationTypes("ru.sysout.annotationprocessing.ToString")
указываются аннотации, которые поддерживает обработчик. Обработчиков может быть несколько — каждый для своих аннотаций.
Метод process()
В классе мы переопределяем метод process(). В него передаются эти аннотации в параметр Set annotations и перебираются в цикле. У нас цикл будет из одной аннотации @ToString.
Сам метод process() также вызывается неоднократно — поскольку генерируется новый исходный код, он тоже проверяется в новых раундах до тех пор, пока не закончится. (Ведь в сгенерированном коде тоже теоретически могут быть аннотации). У нас два раунда, на втором обработчик просто убеждается, что пора выходить.
Итак, что же делается в цикле:
Set<? extends Element> annotatedElements = roundEnv.getElementsAnnotatedWith(annotation);
Map<Boolean, List<Element>> annotatedMethods = annotatedElements.stream().collect(Collectors.partitioningBy(element -> element.getSimpleName().toString().startsWith("get")));
List<Element> getters = annotatedMethods.get(true);
List<Element> otherMethods = annotatedMethods.get(false);
otherMethods.forEach(element -> processingEnv.getMessager().printMessage(Diagnostic.Kind.ERROR, "@ToString must be applied to a getXxx method", element));
if (getters.isEmpty()) {
continue;
}
String className = ((TypeElement) getters.get(0).getEnclosingElement()).getQualifiedName().toString();
List<String> stringGetters = getters.stream().map(getter -> getter.getSimpleName().toString()).collect(Collectors.toList());
try {
writeBuilderFile(className, stringGetters);
} catch (IOException e) {
e.printStackTrace();
}
}
return true;
Мы берем все аннотированные элементы, помещаем их в Map с ключами true и false в зависимости от корректности элемента. (Мы предполагаем, что аннотироваться должны только геттеры.) Далее перекладываем элементы из Map в два списка — правильные и неправильные, для неправильных выбрасываем исключение. У нас в коде все правильные.
Генерация кода
Дальше с помощью метода writeBuilderFile() генерируем код, имея список геттеров:
private void writeBuilderFile(String className, List<String> getters) throws IOException {
String packageName = null;
int lastDot = className.lastIndexOf('.');
if (lastDot > 0) {
packageName = className.substring(0, lastDot);
}
String simpleClassName = className.substring(lastDot + 1);
String toStringsClassName = "ToStrings";
JavaFileObject builderFile = processingEnv.getFiler().createSourceFile(toStringsClassName);
try (PrintWriter out = new PrintWriter(builderFile.openWriter())) {
if (packageName != null) {
out.print("package ");
out.print(packageName);
out.println(";");
out.println();
}
out.print("public class ");
out.print(toStringsClassName);
out.println(" {");
out.println();
out.print(" public static String toString("+simpleClassName+" cat){");
out.println();
out.print(" return ");
String result = getters.stream().map(m -> "cat." + m + "()").collect(Collectors.joining("+\",\"+"));
out.println(result + ";");
out.println(" }");
out.println("}");
}
}
Как видите, код, который пишет код, выглядит некрасиво — все надо записать в файл, начиная с имени пакета и не забыть фигурные скобки, но другого варианта нет.
META-INF/services/javax.annotation.processing.Processor
Для того, чтобы процессор заработал, надо поместить в папку META-INF/services файл javax.annotation.processing.Processor (да, такое длинное имя файла).
И в нем надо указать имя класса процессора:
ru.sysout.annotationprocessing.AnnotationProcessor
Можно не делать это вручную, а включить в проект библиотеку:
<dependency>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service</artifactId>
<version>1.0-rc4</version>
</dependency>
И аннотировать класс AnnotationProcessor:
...
@AutoService(Processor.class)
public class AnnotationProcessor extends AbstractProcessor {
...
}
Тогда файл javax.annotation.processing.Processor будет создан автоматически.
Запуск примера
Сначала надо собрать приложение с процессором annotation-processing. Затем включить его в проект второго приложения annotation-use:
<dependency>
<groupId>ru.sysout</groupId>
<artifactId>annotation-processing</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
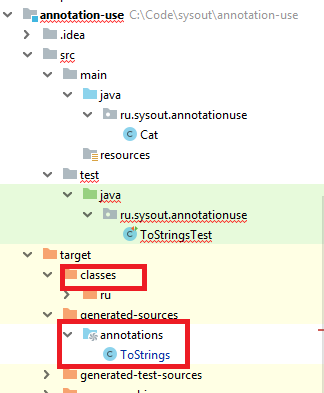
Теперь при компиляции annotation-use в папке generated-sources/annotations появится сгенерированынй исходник класс ToStrings, и в папке classes будет в том числе он в скомпилированном виде:
Итоги
Полный код примеров доступен на GitHub:
Классный пример.
на 27 строке харкод:
out.print(» public static String toString(Cat cat){«);
должно использоваться simpleClassName полученное выше:
out.print(» public static String toString(«+simpleClassName+» cat){«);
Спасибо, исправлено!